In this post, we will figure out what web scraping is, its prerequisites, some project essentials, a step-by-step guide to web scraping with Node.js, and precautions to keep in mind while doing so.
Note: Always hire experienced Node.js developers to do such tasks, as it involves an understanding of different tools and technologies, which is essential to complete this task successfully.
So, What’s Web Scraping Anyway?
Web Scraping is a technique to automate the laborious tasks of gathering information from websites. This term is exchangeably used with web harvesting and web data extraction and can be done manually by a software user. However, it generally refers to automated processes implemented using a web crawler or a bot. Simply put, it is a form of copying in which specific information/data is collected and copied from the web for analysis or retrieval later on.
Why Web Scraping?

There are many cases where you will need web scraping - when you want to collect prices from multiple e-commerce sites for scanning prices, comparing, and analyzing them thoroughly to make the best decision. It could either be for collecting email for sales leads from multiple directories. Or, maybe you are simply thinking about competing with Google by making an intelligent search engine.
What are the Prerequisites for Web Scraping with Node.js?
Since we are pretty clear about web scraping and how it works, it is time to figure out what exactly you need to do using Node.js.
Web scraping can be done using any programming language supporting HTTP and XML or DOM parsing. However, in this easy-to-follow guide, we will be focusing on web scraping using JavaScript in a Node.js environment.
NOTE: The tutorial is based on the assumption that readers are aware of the following:
- JQuery
- Functional programming concepts
- JavaScript and ES6 & ES7 syntax
Some Project Setup Essentials
To begin with the ‘step-by-step guide’ to do web scraping with Node.js, make sure you have done the following.
✅ Installed Node and npm or yarn installed on your machine
✅ A lot of ES&/ES7 will be used in the process, so use Node 8.9.0 or higher and npm 5.2.0 or higher for experiencing complete ES6/7 support.
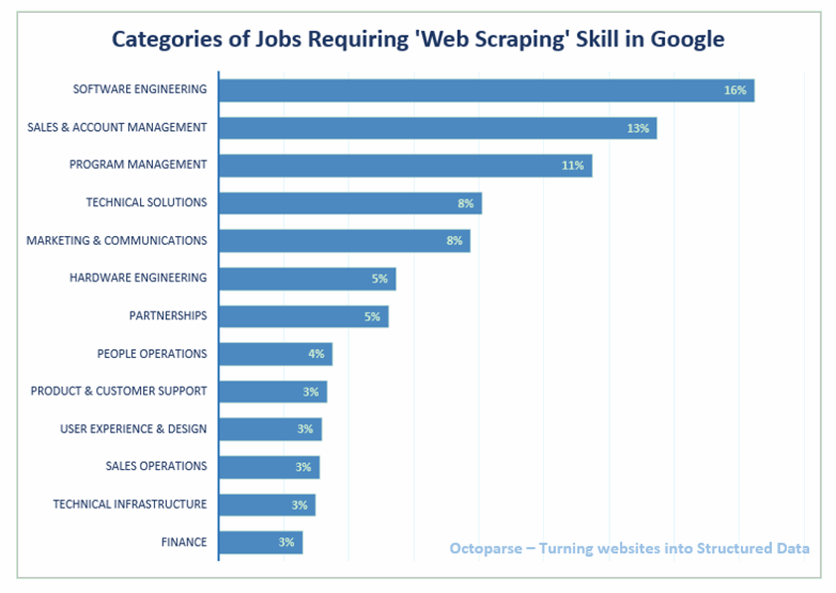
Now, let’s move further to the core packages that we will be using.
Cheerio - Quick, flexible, and lean implementation of core jQuery that makes DOM parsing easy.
Axios- Promise-based HTTP client for Node.js and browser, enabling fetching page contents through HTTP requests.
Express- A flexible and minimal Node.js web app framework offering a reliable set of features for apps (mobile and web).
Lodash - A modern JS utility library that delivers performance, extras, and modularity.
Step-by-Step Guide for Web Scraping with Node.js?

So, here is the step-by-step guide you need to follow to do web scraping using Node.js.
Step 1- Create the Application Directory
Start by creating a new directory for the app and running the command given below to install the essential app dependencies further.
# Create a new directory
mkdir site-scraping
# cd into the new directory
cd site-scraping
# Initiate a new package and install app dependencies
npm init -y
npm install express morgan axios cheerio lodash
Step 2- Now, Setup the ‘Express Server Application’
The second step is to set up an HTTP server app using Express. For that, you will have to create a server.js file in the root directory of your app. Then add the code snippet given below to set up the server.
/_ server.js _/
// Require dependencies
const logger = require('morgan');
const express = require('express');
// Create an Express application
const app = express();
// Configure the app port
const port = process.env.PORT || 3000;
app.set('port', port);
// Load middlewares
app.use(logger('dev'));
// Start the server and listen on the preconfigured port
app.listen(port, () => console.log(`App started on port ${port}.`));
Step 3- Modify npm Scripts
In this step, we will now modify the scripts in the package.json file so that it looks like the snippet mentioned below:
"scripts": {
"start": "node server.js"
}
You can now run the command ‘npm start’ in your terminal, and it will start up your app server on port 3000 (if that is available). At this point, you will not be able to access routes, as we haven’t added them yet to the app.
So, let’s begin with creating some helper functions that we need for web scraping.
Step 4- Create Helper Functions
Create a new app directory in root. Now, create a new file (helpers.js) in the directory you just created to add the content mentioned below:
/_ app/helpers.js _/
const _ = require('lodash');
const axios = require("axios");
const cheerio = require("cheerio");
- Utility Helper Functions Creation
To the helpers.js file you just created, add the following snippet to it:
/_ app/helpers.js _/
///////////////////////////////////////////////////////////////////////////////
// UTILITY FUNCTIONS
///////////////////////////////////////////////////////////////////////////////
/**
**_ Compose function arguments starting from right to left
_** to an overall function and returns the overall function
*/
const compose = (...fns) => arg => {
return **_.flattenDeep(fns).reduceRight((current, fn) => {
if (_**.isFunction(fn)) return fn(current);
throw new TypeError("compose() expects only functions as parameters.");
}, arg);
};
/**
_ Compose async function arguments starting from right to left
_ to an overall async function and returns the overall async function
_/
const composeAsync = (...fns) => arg => {
return .flattenDeep(fns).reduceRight(async (current, fn) => {
if (.isFunction(fn)) return fn(await current);
throw new TypeError("compose() expects only functions as parameters.");
}, arg);
};
/**
_ Enforces the scheme of the URL is https
_ and returns the new URL
_/
const enforceHttpsUrl = url =>
_.isString(url) ? url.replace(/^(https?:)?\/\//, "https://") : null;
/*
Strips number of all non-numeric characters
and returns the sanitized number
/
const sanitizeNumber = number =>
_.isString(number)
? number.replace(/[^0-9-.]/g, "")
: _.isNumber(number) ? number : null;
/*
Filters null values from array
and returns an array without nulls
/
const withoutNulls = arr =>
_.isArray(arr) ? arr.filter(val => !_.isNull(val)) : _[_];
/_**
** Transforms an array of ({ key: value }) pairs to an object
** and returns the transformed object
*/
const arrayPairsToObject = arr =>
arr.reduce((obj, pair) => ({ ...obj, ...pair }), {});
/**_
_ A composed function that removes null values from array of ({ key: value }) pairs
_ and returns the transformed object of the array
*/
const fromPairsToObject = compose(arrayPairsToObject, withoutNulls);
- Request and Response Helper Functions
Now, you will have to add the following to your helper.js file.
/_ app/helpers.js _/
/**
**_ Handles the request(Promise) when it is fulfilled
_** and sends a JSON response to the HTTP response stream(res).
*/
const sendResponse = res => async request => {
return await request
.then(data => res.json({ status: "success", data }))
.catch(({ status: code = 500 }) =>
res.status(code).json({ status: "failure", code, message: code == 404 ? 'Not found.' : 'Request failed.' })
);
};
/**
_ Loads the html string returned for the given URL
_ and sends a Cheerio parser instance of the loaded HTML
*/
const fetchHtmlFromUrl = async url => {
return await axios
.get(enforceHttpsUrl(url))
.then(response => cheerio.load(response.data))
.catch(error => {
error.status = (error.response && error.response.status) || 500;
throw error;
});
};
In this step, we added two new functions:
- sendResponse() : This higher-order functions expects Express HTTP response stream as its argument and returns an async function. If the return promise resolves, a JSON response is sent using res.json(), which will contain the resolved data. In the other case, where the promise rejects, an error JSON response with an apt HTTP status code is sent. Do this to use it in Express.
route:
app.get('/path', (req, res, next) => {
const request = Promise.resolve([1, 2, 3, 4, 5]);
sendResponse(res)(request);
});
Making a GET request will return with this JSON response:
{
"status": "success",
"data": [1, 2, 3, 4, 5]
}
- fetchHTMLfromUrl() : This async functions expected a URL string as its argument. It will use axios.get() to fetch URL content with a promise returned. If it resolves, it will use cheerio.load() with content to create a Cheerio parser instance. If the promise rejects, an error will be shown.
- DOM Parsing Helper Functions
Add the content to the helpers.js file.
/_ app/helpers.js _/
///////////////////////////////////////////////////////////////////////////////
// HTML PARSING HELPER FUNCTIONS
///////////////////////////////////////////////////////////////////////////////
/**
**_ Fetches the inner text of the element
_** and returns the trimmed text
*/
const fetchElemInnerText = elem => (elem.text && elem.text().trim()) || null;
/**
_ Fetches the specified attribute from the element
_ and returns the attribute value
_/
const fetchElemAttribute = attribute => elem =>
(elem.attr && elem.attr(attribute)) || null;
/**
_ Extract an array of values from a collection of elements
_ using the extractor function and returns the array
_ or the return value from calling transform() on array
_/
const extractFromElems = extractor => transform => elems => $ => {
const results = elems.map((i, element) => extractor($(element))).get();
return _.isFunction(transform) ? transform(results) : results;
};
/_*
A composed function that extracts number text from an element,
sanitizes the number text and returns the parsed integer
/
const extractNumber = compose(parseInt, sanitizeNumber, fetchElemInnerText);
/_
_ A composed function that extracts url string from the element's attribute(attr)
_ and returns the url with https scheme
_/
const extractUrlAttribute = attr =>
compose(enforceHttpsUrl, fetchElemAttribute(attr));
module.exports = {
compose,
composeAsync,
enforceHttpsUrl,
sanitizeNumber,
withoutNulls,
arrayPairsToObject,
fromPairsToObject,
sendResponse,
fetchHtmlFromUrl,
fetchElemInnerText,
fetchElemAttribute,
extractFromElems,
extractNumber,
extractUrlAttribute
};
A few more functions are added here, which are as follows:
- fetchElemInnerText() - This function expects an element as argument, which extracts the innerText of the element by calling elem.text().
const $ = cheerio.load('<div class="fullname"> XYZ </div>');
const elem = $('div.fullname');
fetchElemInnerText(elem); // returns => 'XYZ'
It will cut down the white spaces and sleek and trimmed inner text is displayed.
- fetchElemAttribute() - This function expects an attribute as argument and returns another fucntion. Returned function extracts attribute’s value of the attribute by calling elem.attr(attribute)
const $ = cheerio.load('<div class="username" title="XYZ">@xyz</div>');
const elem = $('div.username');
// fetchTitle is a function that expects an element as argument
const fetchTitle = fetchElemAttribute('title');
fetchTitle(elem); // returns => 'XYZ
'
extractFromElems() - A programming technique called currying creates a sequence of functions, each requiring one argument.
extractorFunction -> transformFunction -> elementsCollection -> cheerioInstance
Now, if you want to extract all the names from the file that contains their names as innerText, here’s what you will need to do:
const $ = cheerio.load('<div class="people"><span>xyz</span><span>pqr</span><span>abc</span></div>');
// Get the collection of span elements containing names
const elems = $('div.people span');
// The transform function
const transformUpperCase = values => values.map(val => String(val).toUpperCase());
// The arguments sequence: extractorFn => transformFn => elemsCollection => cheerioInstance($)
// fetchElemInnerText is used as extractor function
const extractNames = extractFromElems(fetchElemInnerText)(transformUpperCase)(elems);
// Finally pass in the cheerioInstance($)
extractNames($); // returns => ['xyz', 'abc', 'pqr']
- extractNumber() - This function expects an element (as argument) and extracts numbers from innerText.
parseInt( sanitizeNumber( fetchElemInnerText(elem) ) );
- extractAttribute() - This function expects attribute in return and the returned function extracts the URL value of the attribute, returning it with HTTPS scheme.
// METHOD 1
const fetchAttribute = fetchElemAttribute(attr);
enforceHttpsUrl( fetchAttribute(elem) );
// METHOD 2: Using extractUrlAttribute()
const fetchUrlAttribute = extractUrlAttribute(attr);
fetchUrlAttribute(elem);
Step 5- Call the URL to Set Up Scraping
In this step, we will create a new file named site.js in the app directory. Add the content mentioned below:
/_ app/site.js _/
const _ = require('lodash');
// Import helper functions
const {
compose,
composeAsync,
extractNumber,
enforceHttpsUrl,
fetchHtmlFromUrl,
extractFromElems,
fromPairsToObject,
fetchElemInnerText,
fetchElemAttribute,
extractUrlAttribute
} = require("./helpers");
// site.com (Base URL)
const SITE_BASE = "https://site.com";
///////////////////////////////////////////////////////////////////////////////
// HELPER FUNCTIONS
///////////////////////////////////////////////////////////////////////////////
/*
Resolves the url as relative to the base site url
and returns the full URL
/
const siteRelativeUrl = url =>
_.isString(url) ? `${SITE_BASE}${url.replace(/^\/*?/, "/")}` : null;
/_*
_ A composed function that extracts a url from element attribute,
_ resolves it to the Site base url and returns the url with https
_/
const extractSiteUrlAttribute = attr =>
compose(enforceHttpsUrl, siteRelativeUrl, fetchElemAttribute(attr));
Here, we will:
- Import lodash
- Define a constant named containing base URL of the website.
Now add:
- siteRelativeUrl()
- extractsiteUrlAttribute()
// METHOD 1
const fetchAttribute = fetchElemAttribute(attr);
enforceHttpsUrl( RelativeUrl( fetchAttribute(elem) ) );
// METHOD 2:
Using extractUrlAttribute()
const fetchUrlAttribute = extractUrlAttribute(attr);
fetchUrlAttribute(elem);
Step 6- Using Extraction Functions
In this step, we will extract several things:
Extracting Social Links
Create extractSocialUrl() function that will extract social network name and URL from a social link. Below is the DOM structure of social link:
<a href="https://github.com/xyz" target="_blank" title="GitHub">
<span class="icon icon-github">
<svg xmlns="http://www.w3.org/2000/svg" xmlns:xlink="http://www.w3.org/1999/xlink" version="1.1" id="Capa_1" x="0px" y="0px" width="50" height="50" viewBox="0 0 512 512" style="enable-background:new 0 0 512 512;" xml:space="preserve">
...
</svg>
</span>
</a>
Calling the extractSocialUrl() function will return object:
{ github: 'https://github.com/xyz' }
Creation function and add content to site.js file
/_ app/site.js _/
///////////////////////////////////////////////////////////////////////////////
// EXTRACTION FUNCTIONS
///////////////////////////////////////////////////////////////////////////////
/_*
_ Extract a single social URL pair from container element
*/
const extractSocialUrl = elem => {
// Find all social-icon <span> elements
const icon = elem.find('span.icon');
// Regex for social classes
const regex = /^(?:icon|color)-(.+)$/;
// Extracts only social classes from the class attribute
const onlySocialClasses = regex => (classes = '') => classes
.replace(/\s+/g, ' ')
.split(' ')
.filter(classname => regex.test(classname));
// Gets the social network name from a class name
const getSocialFromClasses = regex => classes => {
let social = null;
const [classname = null] = classes;
if (_.isString(classname)) {
const _[_, name = null] = classname.match(regex);
social = name ? _.snakeCase(name) : null;
}
return social;
};
// Extract the href URL from the element
const href = extractUrlAttribute('href')(elem);
// Get the social-network name using a composed function
const social = compose(
getSocialFromClasses(regex),
onlySocialClasses(regex),
fetchElemAttribute('class')
)(icon);
// Return an object of social-network-name(key) and social-link(value)
// Else return null if no social-network-name was found
return social && { [social]: href };
};
To extract the class, do this:
const regex = /^(?:icon|color)-(.+)$/;
const extractSocial = onlySocialClasses(regex);
const classNames = 'first-class another-class color-twitter icon-github';
extractSocial(classNames); // returns [ 'color-twitter', 'icon-github' ]
For getSocialFromClasses() function extracts the network name from the first class in the list:
const regex = /^(?:icon|color)-(.+)$/;
const extractSocialName = getSocialFromClasses(regex);
const classNames = [ 'color-twitter', 'icon-github' ];
extractSocialName(classNames); // returns 'twitter'
Extract the href attribute URL:
getSocialFromClasses(regex), onlySocialClasses(regex) and fetchElemAttribute('class')
In case no social network was fetched, null is returned:
{ twitter: 'https://twitter.com/xyz' }
- Extract Post and Stats
Create two additional functions:
- extractPost() and extractStat()
Before that, look into DOM structure:
<div class="card large-card" data-type="post" data-id="2448">
<a href="/tutorials/password-strength-meter-in-angularjs" class="card**img lazy-background" data-src="https://cdn.site.com/7540/iKZoyh9WSlSzB9Bt5MNK_post-cover-photo.jpg">
<span class="tag is-info">Post</span>
</a>
<h2 class="card**title">
<a href="/tutorials/password-strength-meter-in-angularjs">Password Strength Meter in AngularJS</a>
</h2>
<div class="card-footer">
<a class="name" href="/@gladchinda">Glad Chinda</a>
<a href="/tutorials/password-strength-meter-in-angularjs" title="Views">
?️ <span>24,280</span>
</a>
<a href="/tutorials/password-strength-meter-in-angularjs#comments-section" title="Comments">
? <span class="comment-number" data-id="2448">5</span>
</a>
</div>
</div>
DOM structure of the element expected by extractStat().
<div class="profile__stat column is-narrow">
<div class="stat">41,454</div>
<div class="label">Pageviews</div>
</div>
Add content to the app/site.js file.
/_ app/site.js _/
/**
**_ Extract a single post from container element
_**/
const extractPost = elem => {
const title = elem.find('.card__title a');
const image = elem.find('a**[**data-src]');
const views = elem.find("a**[**title='Views'] span");
const comments = elem.find("a**[**title='Comments'] span.comment-number");
return {
title: fetchElemInnerText(title),
image: extractUrlAttribute('data-src')(image),
url: extractSiteUrlAttribute('href')(title),
views: extractNumber(views),
comments: extractNumber(comments)
};
};
/**
_ Extract a single stat from container element
_/
const extractStat = elem => {
const statElem = elem.find(".stat")
const labelElem = elem.find('.label');
const lowercase = val => _.isString(val) ? val.toLowerCase() : null;
const stat = extractNumber(statElem);
const label = compose(lowercase, fetchElemInnerText)(labelElem);
return { [label]: stat };
};
Now create extractPost() function to extract the title, image, URL, views, and comments of a post by
{
title: "Password Strength Meter in AngularJS",
image: "https://cdn.site.com/7540/iKZoyh9WSlSzB9Bt5MNK_post-cover-photo.jpg",
url: "https://site.com//tutorials/password-strength-meter-in-angularjs",
views: 24280,
comments: 5
}
Step 7- Extracting Certain Web Page
extractAuthorProfile() function for extracting complete profile of site’s author.
/_ app/site.js _/
/**
**_ Extract profile from a Site’s author's page using the Cheerio parser instance
_** and returns the author profile object
*/
const extractAuthorProfile = $ => {
const mainSite = $('#sitemain');
const metaSite = $("meta**[**property='og:url']");
const siteHero = mainSite.find('section.hero--site');
const superGrid = mainSite.find('section.super-grid');
const authorTitle = siteHero.find(".profilename h1.title");
const profileRole = authorTitle.find(".tag");
const profileAvatar = siteHero.find("img.profileavatar");
const profileStats = siteHero.find(".profilestats .profilestat");
const authorLinks = siteHero.find(".author-links a**[**target='_blank']");
const authorPosts = superGrid.find(".super-griditem **[**data-type='post']");
const extractPosts = extractFromElems(extractPost)();
const extractStats = extractFromElems(extractStat)(fromPairsToObject);
const extractSocialUrls = extractFromElems(extractSocialUrl)(fromPairsToObject);
return Promise.all(**[**
fetchElemInnerText(authorTitle.contents().first()),
fetchElemInnerText(profileRole),
extractUrlAttribute('content')(metaSite),
extractUrlAttribute('src')(profileAvatar),
extractSocialUrls(authorLinks)($),
extractStats(profileStats)($),
extractPosts(authorPosts)($)
]).then((**[** author, role, url, avatar, social, stats, posts ]) => ({ author, role, url, avatar, social, stats, posts }));
};
/**
_ Fetches the Site profile of the given author
_/
const fetchAuthorProfile = author => {
const AUTHOR_URL = `${SITE_BASE}/@${author.toLowerCase()}`;
return composeAsync(extractAuthorProfile, fetchHtmlFromUrl)(AUTHOR_URL);
};
module.exports = { fetchAuthorProfile };
Promise.all() to extract all the required data.
{
author: 'xyz',
role: 'Author',
url: 'https://site.io/@xyz',
avatar: 'https://cdn.site.io/7540/EnhoZyJOQ2ez9kVhsS9B_profile.jpg',
social: {
twitter: 'https://twitter.com/xyz',
github: 'https://github.com/xyz'
},
stats: {
posts: 6,
pageviews: 41454,
readers: 31676
},
posts: [
{
title: 'Password Strength Meter in AngularJS',
image: 'https://cdn.site.io/7540/iKZoyh9WSlSzB9Bt5MNK_post-cover-photo.jpg',
url: 'https://site.io//tutorials/password-strength-meter-in-angularjs',
views: 24280,
comments: 5
},
...
]
}
Step 8- Create a Route
In this step, we will add a route to the server that will help us fetch any author’s profile on a site.
GET /sitename/:author
/_ server.js _/
// Require the needed functions
const { sendResponse } = require('./app/helpers');
const { fetchAuthorProfile } = require('./app/site');
Copy
Finally, add the route to the server.js file immediately after the middlewares.
/_ server.js _/
// Add the Site author profile route
app.get('/site/:author', (req, res, next) => {
const author = req.params.author;
sendResponse(res)(fetchAuthorProfile(author));
});
Now, we will sendResponse() helper method to send returned profile as a JSON response.
Congrats! We have built an API using the web scraping technique.
- Run npm start command on terminal, launch HTTP testing tool, test API endpoint.
Warnings/Precautions
 The warning requirements for merchants will change in August as Prop. 65 updates with new rules for display signage. (Courtesy of Wikipedia Commons)
The warning requirements for merchants will change in August as Prop. 65 updates with new rules for display signage. (Courtesy of Wikipedia Commons)
Web scraping is actually against the terms of service of most websites. It can lead to banning your IP address if you are doing it more frequently or maliciously.
Conclusion
You can hire Node.js developers to do web scraping with Node.js for you. But, it is essential to keep the precautions in mind and do it safely for ensuring everything is being done correctly and under the supervision of an expert developer.
At Your Team In India, we have a pool of certified Node.js engineers. Need help setting up a dedicated team of developers in India? Connect with us our business head now and get a free consultation.






